Performance Benchmarks
Tests were performed in July 2016 with an early version of the 64 bit version of Earth Volumetric Studio to determine the limits of model size and kriging settings that were practical depending on your hardware configuration. The tests were conducted on a desktop computer with the following hardware and OS:
- Windows 10 Pro 64 bit
- Intel Core i7-5820k CPU @ 3.30 GHz: 6 Cores, 12 Logical Processors
- 32 GB of 2800 MHz RAM
- NVIDIA GeForce GTX 980 Ti Graphics
In general, it is difficult to accurately estimate the time to krige a particular dataset for a given resolution (number of nodes). The spatial distribution of the data does have an impact on computation time as does your computer hardware and other software running on it. However, these graphs are intended to provide some guidance not only on expected compute times, but also on hardware requirements as a function of grid resolution and kriging settings.
Two primary issues were investigated:
- Total model size as measured by the total number of nodes
- Maximum dataset size which can be kriged with "Use All Points" option.
For both issues we recorded the compute time as well as the required RAM in GB.
At this point, we do not believe there are any practical limits on model or dataset size other than hardware limitations and patience.
Let's begin with the first issue, total model size.
We have long had customer who wished to create much finer models than was possible with the 32-bit version of our software. The number one reason for wanting a finer grid was to be able to create a 3D volumetric models which could inherit the high grid resolutions of 2D topography from DEMs & Grids. Historically, the high resolution was not required in order to resolve nuances in the data, however the recent trends to collect high resolution data with MIP technology or geophysics instrumentation such as 3D Resistivity Surveys has definitely been moving in the direction of needing larger model sizes in order to better honor the data.
The first graph below shows the results of 9 test cases kriging grids ranging from 1 million to 160 million nodes. The data used in 3d estimation was railyard.apdv which has 273 samples, and it was kriged using the Use All Points option.

What we can see from this graph is quite encouraging. On the test system with 32 GB of RAM, it appears that we used all available memory once the models size reached 80 million nodes, but we were able to go to 160 million nodes with no significant drop in relative speed though it seems to be using some virtual memory.
The kriging times for our sample dataset with 273 points were ~3 microseconds per node or 3 seconds per million nodes, with a linear relationship. The linear relationship is important, (and will not continue for the other issues being investigated), since it means that as our models get bigger the time will increase proportionately (up to the limits of your computer hardware).
However, I must point out that if you have only 273 samples in your dataset, you certainly don't need a 20 million node grid and therefore, you need to read on to understand these issues better.
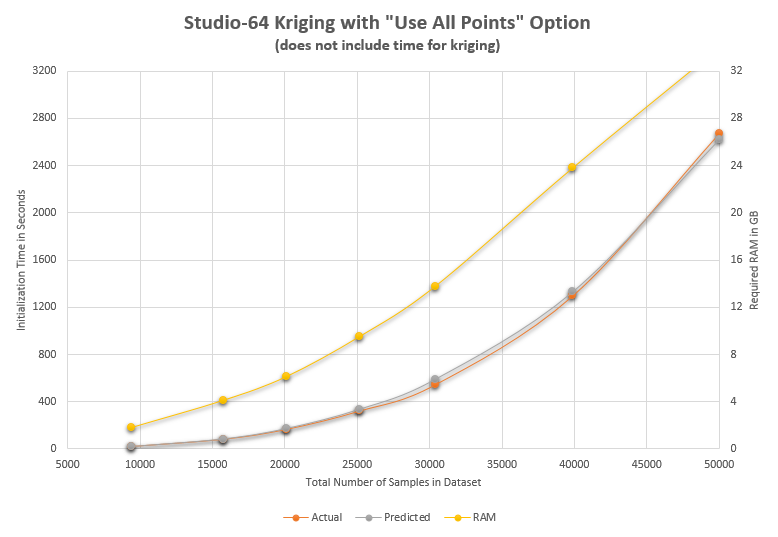
Our next graph investigates just how big our dataset can be that we can still use the "Use All Points" option. It is beyond the scope of this topic to explain just how important this is, but those who have been working with EVS on large MIP datasets understand this issue well. In the 32-bit versions of our software, the limit was between 3500 and 4000 samples. As you see above, it is much-much larger. But there is a price to pay: TIME.
We have tested datasets up to 50,000 samples and the graph above reports the Initialization time, not the kriging time. Since the "Use All Points" option has a large Initialization time, this is a critical parameter, and it is proportional to the third power of the number of samples. So, even though we can now use datasets which are over 12 times larger than was previously possible, the Initialization time will be 123= 1,728 longer for a 48,000 sample dataset vs a 4,000 sample dataset.
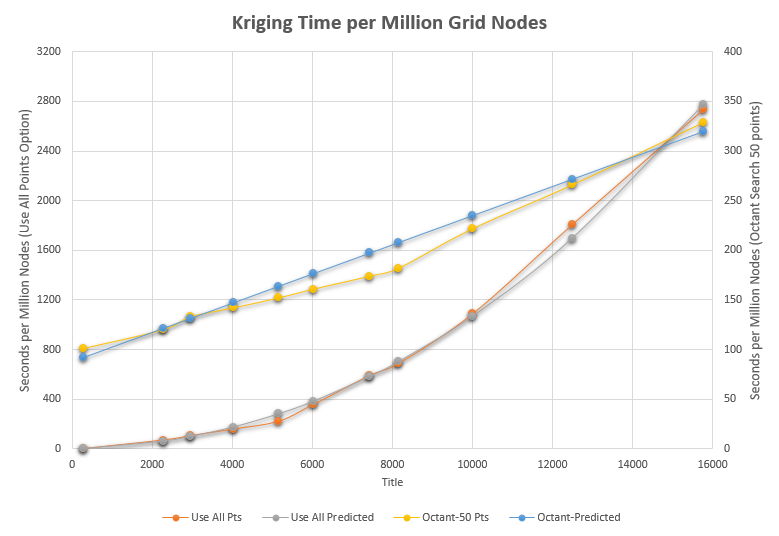
Our final graph shows computation time per million nodes as a function of total number of samples in the dataset. The relationship is roughly proportional to the 2.2 power for the "Use All Points" option, but if we revert to Octant Search with (up to) 50 points per octant (max 200 points) the relationship is much more linear and the times are dramatically less. Additionally, Octant Search does not have the substantial initialization time. Using these graphs we can predict what our total computation time would be if we wanted to krige the following cases:
CASE 1
- 20 million node grid
- 8,000 samples in the dataset
- Use All Points Option
- Initialization: actually ~15 seconds
- 660 seconds = 11 minutes per million nodes
- 3.67 hours total kriging time
CASE 2
- 15 million node grid
- 14,000 samples in the dataset
- Use All Points Option
- Initialization: ~58 seconds
- 2350 seconds = 39.2 minutes per million nodes
- 9.8 hours kriging time
CASE 3
As a final case we'll consider the second case but use Octant Search with 50 points:
- 15 million node grid
- 14,000 samples in the dataset
- Octant Search 50 Points
- 290 seconds = 4.83 minutes per million nodes
- 1.2 hours kriging time